 하둡 운영
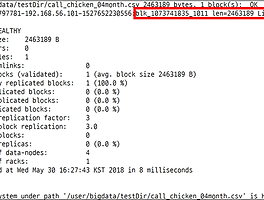
데이터는 SK데이터허브( https://www.bigdatahub.co.kr/index.do)에서 받았음 데이터의 크기: 2.95MB 하둡 구성 호스트 명 하둡2 설치 내용 server01 주키퍼, 액티브 네임노드, 저널노드, 데이터노드, 리소스매니저 server02 주키퍼, 스탠바이 네임노드, 저널노드, 데이터노드, 노드매니저 server03 주키퍼, 저널노드, 데이터노드, 노드매니저 server04 데이터노드, 노드매니저 ■ HDFS 운영 - 네임노드에게 클라이언트는 권한을 받으면 데이터노드에 접근해 데이터 저장 - 데이터는 블록 단위 (기본 64MB 또는 128MB)로 나눠져 저장 - HDFS의 블록 복제수는 기본적으로 3개 - 네임노드는 데이터 노드에 장애가 나면 그 데이터노드의 블록들을 다른 서..
하둡 운영
데이터는 SK데이터허브( https://www.bigdatahub.co.kr/index.do)에서 받았음 데이터의 크기: 2.95MB 하둡 구성 호스트 명 하둡2 설치 내용 server01 주키퍼, 액티브 네임노드, 저널노드, 데이터노드, 리소스매니저 server02 주키퍼, 스탠바이 네임노드, 저널노드, 데이터노드, 노드매니저 server03 주키퍼, 저널노드, 데이터노드, 노드매니저 server04 데이터노드, 노드매니저 ■ HDFS 운영 - 네임노드에게 클라이언트는 권한을 받으면 데이터노드에 접근해 데이터 저장 - 데이터는 블록 단위 (기본 64MB 또는 128MB)로 나눠져 저장 - HDFS의 블록 복제수는 기본적으로 3개 - 네임노드는 데이터 노드에 장애가 나면 그 데이터노드의 블록들을 다른 서..







