■ 하이브(Apache Hive)

1) 하둡 이전의 (빅)데이터 분석업무를 맡은 사람들은 SQL등을 활용하여 업무를 수행했음
2) 하지만 하둡의 맵리듀스는 애플리케이션을 구현해야 처리 / 분석을 할 수 있었음
3) 그래서 기존의 데이터분석가를 위해 ‘페이스북’이 하이브를 개발
4) 현재는 하둡플랫폼으로 빅데이터를 처리하는 회사에서 다양하게 사용하였음
- 페이스북, 넷플릭스 등
■ 하이브(Apache Hive)의 개념
1) 하둡 데이터(파일)를 SQL과 비슷한 쿼리를 이용해서 다룰 수 있게 해줌
- 하이브QL 지원
2) DW(Data Warehouse) 어플리케이션에 적합
- 하둡의 기반으로 대량의 데이터를 배치 연산 가능
- 레코드 단위 갱신/삭제
- 트랜잭션 제한적인 지원(0.13 버전 이전에는 아예 지원을 안했음)
transaction = true 옵션
ORC format
- HiveQL로 분석, 데이터 작업은 용이하나 내부적으로는 Mapreduce로 변환되어 진행되기 때문에 빠른 처리는 불가능
■ 하이브 테이블
- RDBMS 테이블과 유사한 스키마를 가짐
- 파일 시스템의 파일을 테이블 데이터로 사용
- 테이블 종류
• 관리(managed)테이블 : 하이브가 관리하며 테이블 삭제 시 메타 정보와 파일 함께 삭제 됨
• 외부(external)테이블 : 테이블 생성 시 설정한 경로로 데이터를 저장하며 테이블 삭제 시 메타 정보만 삭제되고 데이터가 보존됨
- 하이브 데이터 타입
■ 예제
CentOS 7 에서 진행했으며, 당시 hive 버전은 3.1.2 입니다.
SK Big Data Hub(https://www.bigdatahub.co.kr/index.do)
- SK 텔레콤에서 수집한 데이터를 SK Big Data Hub 가입후 무료로 이용 가능
- CALL_CHICKEN_07MONTH.csv: 서울 지역 치킨집에 대한 한달 통화량을 기반으로 지역별 이용 현황 데이터를 제공
◦ 시도/시군구/읍면동: 이용자의 발신지역을 기준으로 서울지역 동단위까지 제공
◦ 연령대: 10세 단위로 6개 연령대(10대, 20대, 30대, 40대, 50대, 60대 이상)
◦ 통화건수: 이용자의 치킨집 통화건수(통화량 5건 미만은 5건으로 표시)
- 업로드한 csv파일에 따옴표와 컬럼명이 있다면 제거
#따옴표 제거
$ find . -name CALL_CHICKEN_07MONTH.csv -exec perl -pi -e 's/"//g' {} \;
#맨 위 한줄 제거(컬럼명 제거)
$ sed -e '1d' CALL_CHICKEN_07MONTH.csv > CALL_CHICKEN_07MONTH_new.csv
#파일 원래 이름으로 변경
$ mv CALL_CHICKEN_07MONTH_new.csv CALL_CHICKEN_07MONTH.csv
◦ find: 디스크에 저장된 파일/디렉터리 검색
◦ 문자열찾은 후 치환: find . -exec perl -pi -e 's/찾을문자열/바꿀문자열/g' {} \;
◦ sed: 필터링과 텍스트를 변환하는 스트림 편집기
- 관리테이블 생성
CREATE TABLE 테이블명 (칼럼명 칼럼 타입, ...)
COMMENT '테이블 설명'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS '파일 포맷형식';
◦ CREATE TABLE 테이블명 (칼럼명 칼럼 타입, …) -> 테이블 만드는 최소 조건
◦ ROW FORMAT: 해당 테이블 내의 데이터가 어떤 형식으로 저장될지 설정
◦ 필드를 콤마 기준으로 구분(만약 필드가 탭으로 구분되어있다면: \t)
◦ 행과 행은 \n 값으로 구분
◦ STORED AS: 데이터 저장 파일 포맷
◦ COMMENT: 테이블의 설명을 참고용으로 등록
◦ DBNAME: 데이터베이스명 -> 생략시 default DB 사용
- 하이브로 call_chicken_07month 테이블 생성
CREATE TABLE call_chicken_07month(sysdate STRING, dayOfWeek STRING, gender STRING, age STRING , city STRING , district STRING , town STRING, type STRING, calls INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;

- 외부 테이블 생성(경로 커스텀)
CREATE EXTERNAL TABLE call_chicken_07month_ex(sysdate STRING, dayOfWeek STRING, gender STRING, age STRING , city STRING , district STRING , town STRING, type STRING, calls INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hadoop/call_chicken_07month';
◦ EXTERNAL 키워드로 외부 테이블 생성
◦ LOCATION: 데이터를 저장할 경로 생성
◦ 외부 테이블은 Drop을 해도 데이터가 보존됨
◦ HDFS에서 외부테이블로 저장한 데이터 확인 가능

- 파티션 된 테이블
CREATE TABLE chicken_calls(sysdate STRING, dayOfWeek STRING, gender STRING, age STRING , city STRING , district STRING , town STRING, type STRING, calls INT)
PARTITIONED BY (year string, month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
◦ PARTITIONED BY (파티션키 파티션타입): 테이블의 파티션 설정
◦ 파티션키는 해당 테이블의 새로운 칼럼으로 추가됨
◦ 하이브는 쿼리문의 수행 속도를 향상 시키기 위해 파티션 설정 가능
◦ 파티션을 설정하면 해당 테이블의 데이터를 파티션 별로 디렉터리 생성해 저장
◦ 아래의 사진은 생성된 테이블에 데이터를 로딩한 결과

■ 데이터 로드
- HDFS에서 테이터를 로딩
LOAD DATA INPATH '디렉터리 경로'
OVERWRITE INTO TABLE 테이블 명;
◦ LOAD DATA INPATH '디렉토리 경로': 디렉토리에 포함된 모든 파일을 로딩
◦ OVERWRITE: 기존의 파일들을 삭제
- 로컬에서 데이터를 로딩
LOAD DATA LOCAL INPATH '디렉터리 경로'
OVERWRITE INTO TABLE 테이블 명;
◦ LOCAL: 로컬 파일을 테이블 데이터 경로에 로딩
- 파티션된 테이블에 데이터 로딩
LOAD DATA local INPATH '디렉토리 경로'
OVERWRITE INTO TABLE 테이블 명
PARTITION (파티션 키='값');
- 외부(로컬) 데이터를 하이브 테이블로 로딩하기
/home/bigdata/example_data/ 경로에 있는 CALL_CHICKEN_07MONTH.csv 업로드
LOAD DATA LOCAL INPATH '/home/bigdata/example_data/CALL_CHICKEN_07MONTH.csv'
OVERWRITE INTO TABLE call_chicken_07month;

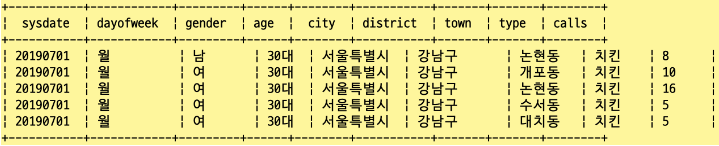
- select로 call_chicken_07month 테이블의 데이터를 5개만 확인
SELECT sysdate, dayofweek, gender, age, city, district, town, type, calls
FROM call_chicken_07month limit 5;
- 외부(로컬) 데이터를 하이브 파티션 테이블로 로딩하기 :
/home/bigdata/example_data/ 경로에 있는 CALL_CHICKEN_07MONTH.csv 업로드
LOAD DATA LOCAL INPATH '/home/bigdata/example_data/CALL_CHICKEN_07MONTH.csv'
OVERWRITE INTO TABLE chicken_calls
PARTITION(year='2019', month='07');
- select로 chicken_calls 테이블의 데이터를 5개만 확인
SELECT sysdate, dayofweek, gender, age, district, calls, year, month
FROM chicken_calls
limit 5;
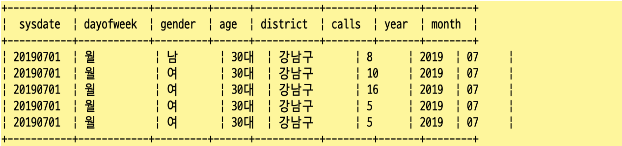
◦ 파티션 키(year, month)가 컬럼이 된 것을 확인
■ 테이블 지우기
- 테이블 구조 + HDFS에 저장된 데이터 모두 삭제
DROP TABLE [IF EXISTS] 테이블명;
'data engineering' 카테고리의 다른 글
| Kafka broker 연결 안됨 (0) | 2021.03.28 |
|---|---|
| Hbase 개요 (0) | 2020.01.31 |
| Flume 설치 및 간단한 예제 (0) | 2018.09.26 |
| Flume 개요 (0) | 2018.09.11 |
| 하둡 운영 (2) | 2018.09.04 |



